Blog
Google’s TPU 8t and TPU 8i address agentic AI

They are specifically designed for AI training (TPU 8t) and inference (TPU 8i), says the search giant, and for working with Google DeepMind.
 “These two chips are designed to power our custom-built supercomputers, to drive everything from cutting-edge model training and agent development, to massive inference workloads,” writes Amin Vahdat, Google’s Chief Technologist for AI & Infrastructure, right.
“These two chips are designed to power our custom-built supercomputers, to drive everything from cutting-edge model training and agent development, to massive inference workloads,” writes Amin Vahdat, Google’s Chief Technologist for AI & Infrastructure, right.
“TPUs have been powering leading foundation models, including Gemini, for years. These 8th generation TPUs together will deliver scale, efficiency and capabilities across training, serving and agentic workloads.”
The announcement was made at Google Cloud Next ’26, but technical details are scarce.
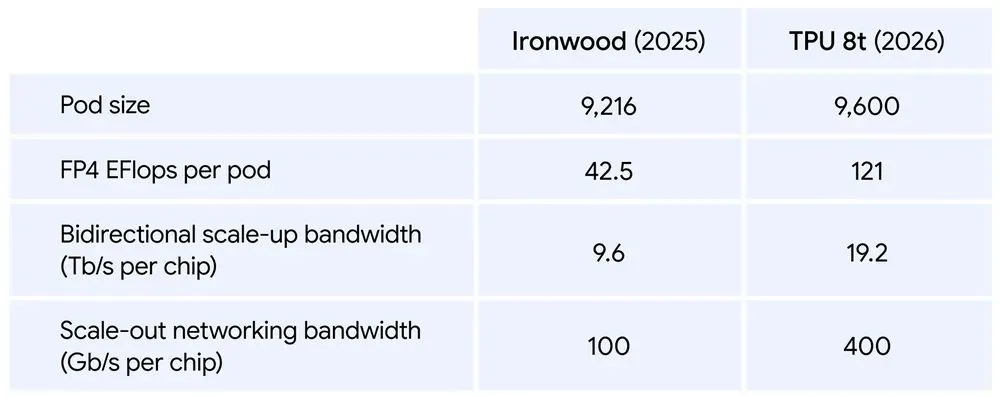
TPU 8t
Google says a single TPU 8t superpod (a customised network of 64 boards) now scales to 9,600 chips and two petabytes of shared high bandwidth memory. This is with double the interchip bandwidth of the previous generation. It says the architecture delivers 121 ExaFlops of compute, which allows the most complex models to use a single, massive pool of memory.
It also uses the company’s Virgo Network, which is an AI-oriented networking system, along with JAX and Pathways software. It means, says Google, the TPU 8t can provide near-linear scaling for up to a million chips in a single logical cluster.
A comparison of TPU 8t and its predecessor, codenamed Ironwood, is shown below.
TPU 8i
In terms of TPU 8i, for AI inferencing, Google states the system delivers nearly 3x the compute performance per pod over the previous generation.
Details include that the TPU 8i pairs 288 GB of high-bandwidth memory with 384MB of on-chip SRAM. This is 3x more than the previous generation, and can keep a model’s active working set entirely on-chip.
Google also says it has doubled the physical CPU hosts per server, moving to its custom Axion Arm-based CPUs.
“By using a non-uniform memory architecture (NUMA) for isolation, we have optimized the full system for superior performance,” states Vahdat.
For modern Mixture of Expert (MoE) models, Google states it has doubled the Interconnect (ICI) bandwidth to 19.2 Tb/s. Its new Boardfly architecture aims to “reduce the maximum network diameter by more than 50%, ensuring the system works as one cohesive, low-latency unit”.
A new on-chip Collectives Acceleration Engine (CAE) offloads global operations, reducing on-chip latency by up to 5x, to minimise lag.
You can read more on this Google blog post.
TPU2
Back in 2017 Google announced its second-generation TPU, the TPU2, delivering a now relatively-modest 45Tflops.
A system board with four TPU2s would deliver 180Tflops and a customised network of 64 boards, called a TPU pod, 11.5 petaflops.
See all our Google content.